Chapter 11 Nonlinear Relationships and Multiple Linear Regression
In the last unit, we learned how to describe linear relationships between two variables, X and Y. Correlation was used when we wanted to measure the association between the two variables. This was appropriate when when, based on our “domain knowledge” (agronomy or our other specialty), we did not have insight into whether one variable affected the other, or whether a third, unknown variable affected the value of both. Simple Linear Regression was used when we had insight into the causation that linked two variables: we knew or hypothesized that a single response variable, \(Y\), was affected (and could be predicted) by a single predictor variable, \(X\).
Simple linear regression, however, has its limitations. First, simple linear regression is often too inadequate for modelling more complex systems. For example, a simple linear regression model might fit the effect of rainfall on corn yield. But we all realize that a prediction of corn yield based on rainfall alone will not be particularly accurate.
If we included additional predictor variables, such as a measure of heat (cumulative growing degree days) or soil texture (water holding capacity or clay content), we would likely predict yield more accurately. Multiple Linear Regression allows us to build model the relationship between a response variable, \(Y\), and multiple predictor variables, \(X_1\), \(X_2\), \(X_3\), etc.
Second, a linear model assumes the relationship between Y and X can be fit with a straight line. If you have taken a soil science course, however, you learned about Leibig’s Law of the Minimum and the Mitscherlich Equation that describe the relationship between nutrient availability and plant biomass. These relationships are curved and need to be fit with Nonlinear Regression models.
In this unit, we will learn how to use multiple linear regression to model yield responses to environment. We will also learn how to model nonlinear relationships, such as fertilizer response and plant growth
11.1 Multiplie Linear Regression
In multiple linear regression, response variable Y is modeled as a function of multiple X variables:
\[ Y = \mu + X_1 + X_2 + X_3 ... X_n\]
11.1.1 Case Study: Modelling Yield by County
We are going to work with a county-level dataset from Purdue university that includes soil characteristics, precipitation, corn, and soybean yield. I’ve become best-friends with this dataset during the past few years and have combined it with county-level weather data to build complex yield models. The authors used land use maps to exclude any acres not in crop production. Click the following link to access a little app with which to appreciate this dataset.
Here is the top of the data.frame:
| county | state | stco | ppt | whc | sand | silt | clay | om | kwfactor | kffactor | sph | slope | tfactor | corn | soybean | cotton | wheat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Abbeville | SC | 45001 | 562.2991 | 22.94693 | 39.26054 | 21.38839 | 39.351063 | 36.92471 | 0.2045719 | 0.2044325 | 5.413008 | 42.59177 | 4.666834 | 57.75000 | 16.75385 | 525.500 | 30.17500 |
| Acadia | LA | 22001 | 751.1478 | 37.83115 | 12.82896 | 54.19231 | 32.978734 | 105.79133 | 0.4432803 | 0.4431914 | 6.370533 | 34.92266 | 4.855202 | 92.42500 | 28.72857 | NA | 38.11000 |
| Accomack | VA | 51001 | 584.6807 | 18.56290 | 74.82042 | 16.82072 | 8.358863 | 103.11425 | 0.2044544 | 0.2044544 | 5.166446 | NA | 4.011007 | 116.99714 | 30.44857 | 575.125 | 56.07407 |
| Ada | ID | 16001 | 124.9502 | 15.54825 | 44.49350 | 40.48000 | 15.026510 | 77.61499 | 0.4106704 | 0.4198545 | 7.648190 | NA | 2.853957 | 145.74138 | NA | NA | 97.26296 |
| Adair | IA | 19001 | 598.4478 | 28.91851 | 17.82011 | 48.44056 | 33.739326 | 259.53255 | 0.3541369 | 0.3541369 | 6.215139 | 55.24201 | 4.691089 | 133.02571 | 41.70857 | NA | 34.04000 |
| Adair | KY | 21001 | 698.6234 | 20.87349 | 15.66781 | 48.16733 | 36.164866 | 73.05356 | 0.3166089 | 0.3725781 | 5.351832 | 37.65075 | 4.119289 | 95.76765 | 37.50000 | NA | 37.42105 |
How does corn yield respond to soil properties and precipitation in Minnesota and Wisconsin? Let’s say we want to model corn yield as a function of precipitation (ppt), percent sand (sand), percent clay (clay), percent organic matter (om) and soil pH (spH)? Our linear additive model would be:
\[ Y = \alpha + \beta _1 ppt + \beta _2 sand + \beta _3 clay + \beta _4 om + \beta _5 sph + \epsilon\]
First, we need to filter the dataset to MN and WI
counties_mn_wi = counties %>%
filter(state %in% c("MN", "WI"))
head(counties_mn_wi) %>%
kableExtra::kbl()| county | state | stco | ppt | whc | sand | silt | clay | om | kwfactor | kffactor | sph | slope | tfactor | corn | soybean | cotton | wheat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adams | WI | 55001 | 548.2443 | 15.67212 | 78.38254 | 11.71815 | 9.899312 | 438.3402 | 0.1170651 | 0.1179408 | 6.068121 | 65.21191 | 4.521995 | 112.78000 | 34.08857 | NA | 40.32500 |
| Aitkin | MN | 27001 | 485.5737 | 28.30823 | 47.94610 | 38.02355 | 14.030353 | 1760.8355 | 0.3114794 | 0.3126979 | 6.405352 | 25.42843 | 3.700648 | 83.21111 | 27.98462 | NA | 30.64000 |
| Anoka | MN | 27003 | 551.9312 | 24.75840 | 75.16051 | 18.69882 | 6.140666 | 1787.7790 | 0.1505643 | 0.1513100 | 6.248463 | 28.34023 | 4.432518 | 101.93429 | 27.70000 | NA | 35.05000 |
| Ashland | WI | 55003 | 495.9158 | 21.11778 | 43.10370 | 32.20112 | 24.695183 | 274.1879 | 0.2977456 | 0.3111864 | 6.638459 | 62.67817 | 4.265288 | 88.78421 | 24.00000 | NA | 32.82857 |
| Barron | WI | 55005 | 528.5029 | 22.30522 | 58.10407 | 31.03742 | 10.858506 | 231.5082 | 0.2886149 | 0.2924627 | 5.710398 | 48.65562 | 3.943001 | 111.98000 | 33.79429 | NA | 44.49630 |
| Bayfield | WI | 55007 | 490.7059 | 21.75064 | 34.08119 | 29.80771 | 36.111094 | 137.1594 | 0.2927169 | 0.2933493 | 7.166786 | 63.60773 | 4.636175 | 85.72857 | 22.40000 | NA | 31.21429 |
To fit our model, we use the linear model lm() function of R. For multiple regression, we don’t list any interactions between the terms.
model_mn_wi = lm(corn ~ ppt + sand + clay + om + sph, data=counties_mn_wi)
summary(model_mn_wi)##
## Call:
## lm(formula = corn ~ ppt + sand + clay + om + sph, data = counties_mn_wi)
##
## Residuals:
## Min 1Q Median 3Q Max
## -42.432 -4.342 1.108 7.035 23.278
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -189.02125 22.76727 -8.302 5.52e-14 ***
## ppt 0.37140 0.02165 17.159 < 2e-16 ***
## sand -0.33075 0.10746 -3.078 0.00248 **
## clay -1.16506 0.24579 -4.740 4.92e-06 ***
## om -0.01679 0.00307 -5.469 1.85e-07 ***
## sph 24.21303 2.02991 11.928 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.61 on 150 degrees of freedom
## (3 observations deleted due to missingness)
## Multiple R-squared: 0.7651, Adjusted R-squared: 0.7573
## F-statistic: 97.71 on 5 and 150 DF, p-value: < 2.2e-16Let’s go through the results. The first output item, the Call, is the linear model we gave to R.
The second item, residuals, describes the distribution of residuals around the regression model. We can see the minimum residual is 42 bu/acre below the predicted value. The maximum residual is 23 bu/acre above the predicted value. The middle 50% (between 1Q and 3Q) were between 4.3 below and 7.0 above the predicted values.
The Coefficients table is the highlight of our output. The table shows the estimated slopes \(\beta_1, \beta_2, \beta_3...\beta_n\) associated with each environmental factor, plus the individual t-tests of their significance. We can see that each factor of our model is significant.
In the bottom, we see that three observations were deleted due to missingness (they didn’t have a value for each factor). Two \(R^2\)s are presented. The multiple \(R^2\) is the proportion of the total variance in the model explained by our regression model. This is the same concept as for simple linear regression. Our value is 0.77, which is pretty good for an environmental model like this, especially because we did not include any temperature data.
11.1.2 Beware of Bloated Models
Multiple Linear Regression is a powerful tool, but it generally pays to be conservative in how many factors you include in a model. The more terms you include, the more you are likely to encounter problems with overfitting, multicollinearity, and heteroscedasticity.
11.1.2.1 Overfitting
Every model contains fixed terms (which the model is meant to measure and predict) and random terms, such as error, which are beyond the scope of the model to predict. Not only that: since the error effect is random, it would be wrong for a model to try to predict it. If we add enough factors to a model, however, it will do exactly that. It will overfit the data. The problem with overfitting is that the model contorts itself to fit every nook and crany of one dataset – but fails to accurately predict values for additional datasets that, randomly, have different error structures.
Here is an analogy. You let your spouse or best friend borrow your car. When they return it, the seating settings are completely messed up. The lumbar support is either poking you in your but or about to break your neck. You either can’t reach the pedals and the steering wheel, or the seat is up so far you cannot even get in the car. In addition, the climate control is too hot or too cold. And, seeing what they left on the radio, you start to rethink the whole relationship.
This is exactly the problem with overfitting. The more we perfect the fit of a model one dataset, the more unlikely it is to make accurate predictions for another dataset.
Adding factors to a model will always increase the \(R^2\) value, even if the new factor has nothing to do with what the model is predicting. For fun, lets create a column that randomly assigns an average number of Grateful Dead concerts attended per person, from 1 to 40, to each county.
| county | state | stco | ppt | whc | sand | silt | clay | om | kwfactor | kffactor | sph | slope | tfactor | corn | soybean | cotton | wheat | gd_concerts |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adams | WI | 55001 | 548.2443 | 15.67212 | 78.38254 | 11.71815 | 9.899312 | 438.3402 | 0.1170651 | 0.1179408 | 6.068121 | 65.21191 | 4.521995 | 112.78000 | 34.08857 | NA | 40.32500 | 18 |
| Aitkin | MN | 27001 | 485.5737 | 28.30823 | 47.94610 | 38.02355 | 14.030353 | 1760.8355 | 0.3114794 | 0.3126979 | 6.405352 | 25.42843 | 3.700648 | 83.21111 | 27.98462 | NA | 30.64000 | 27 |
| Anoka | MN | 27003 | 551.9312 | 24.75840 | 75.16051 | 18.69882 | 6.140666 | 1787.7790 | 0.1505643 | 0.1513100 | 6.248463 | 28.34023 | 4.432518 | 101.93429 | 27.70000 | NA | 35.05000 | 34 |
| Ashland | WI | 55003 | 495.9158 | 21.11778 | 43.10370 | 32.20112 | 24.695183 | 274.1879 | 0.2977456 | 0.3111864 | 6.638459 | 62.67817 | 4.265288 | 88.78421 | 24.00000 | NA | 32.82857 | 37 |
| Barron | WI | 55005 | 528.5029 | 22.30522 | 58.10407 | 31.03742 | 10.858506 | 231.5082 | 0.2886149 | 0.2924627 | 5.710398 | 48.65562 | 3.943001 | 111.98000 | 33.79429 | NA | 44.49630 | 33 |
| Bayfield | WI | 55007 | 490.7059 | 21.75064 | 34.08119 | 29.80771 | 36.111094 | 137.1594 | 0.2927169 | 0.2933493 | 7.166786 | 63.60773 | 4.636175 | 85.72857 | 22.40000 | NA | 31.21429 | 3 |
And then let’s check out our model:
##
## Call:
## lm(formula = corn ~ ppt + sand + clay + om + sph + gd_concerts,
## data = counties_mn_wi_gd)
##
## Residuals:
## Min 1Q Median 3Q Max
## -41.881 -4.347 1.033 6.632 23.862
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.897e+02 2.284e+01 -8.304 5.66e-14 ***
## ppt 3.707e-01 2.173e-02 17.059 < 2e-16 ***
## sand -3.334e-01 1.078e-01 -3.093 0.00236 **
## clay -1.169e+00 2.464e-01 -4.745 4.84e-06 ***
## om -1.690e-02 3.082e-03 -5.483 1.75e-07 ***
## sph 2.426e+01 2.036e+00 11.917 < 2e-16 ***
## gd_concerts 4.393e-02 7.361e-02 0.597 0.55155
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.64 on 149 degrees of freedom
## (3 observations deleted due to missingness)
## Multiple R-squared: 0.7656, Adjusted R-squared: 0.7562
## F-statistic: 81.13 on 6 and 149 DF, p-value: < 2.2e-16See? Our Multiple \(R^2\) increased slightly from 0.765 to 0.766. While this example is absurd, it points to a temptation for statisticians and data scientists: keep adding terms until the \(Multiple R^2\) is an accepted value. Less nefariously, the researcher may just thinK the more variables the researcher can add, the better. We can now see this is wrong.
11.1.2.2 Multicollinearity
Another problem that can occur as we add factors to our model is multicollinearity. Our linear model assumes that each factor has an independent effect on the response variable. We know, however, that is not always the case. For example, all sorts of weather and soil factors in our model can be related. Cloudy days associated with precipitation may decrease temperature. Warm temperatures may reduce soil moisture. Areas with greater precipitation will tend to have more woody vegetation, leading to lower soil pH and soil organic matter. Coarser soils, which are better drained, will tend to have lower soil organic matter.
Here is a hypothetical scenario: suppose we look at the regression of yield on precipitation and pH and conclude yield is significantly affected by both of them. Do we know that soil pH caused the change in yield? No, it’s possible that precipitation affected both pH and yield so that they appeared to change together. That’s not to say we can’t include all of these factors in our model. But we need to make certain that they are directly causing changes to the response variable, rather than responding with the response variable to a third variable in the model.
11.1.2.3 Heteroscedasticity
The third problem we can have with a multiple linear regression model is that it is heteroscedastic. This indimidating term refers to unequal variances in our model. That is, the variance of observed yields varies markedly with the value being predicted. Multiple linear regression, like other linear models, assumes that the variance will be the same along all levels of the factors in the model. When heteroscedasticity – unequal variances – occurs, it jeopardizes our ability to fit the that factor. Our least squared estimate for that factor will be more influenced by factor levels with greater variances and less influences by levels with lesser variances.
One of the causes of heteroscedasticity is having many predictors – each with their own scales of measure and magnitudes – in a model. Since linear regression relies on least squares – that is, minimizing the differences between observed and predicted values – it will be more includenced by factors with greater variances than factors with small variances, regardless of how strongly each factor is correlated with yield.
The end result is that the regression model will fit the data more poorly. Its error will be greater and, thus, its F-value and p-value will be reduced. This may lead us to conclude a factor or the overall model does not explain a significant proportion of the variation in data, when in fact it does. In other words, we may commit at Type II error.
11.1.3 Methods for Avoiding Bloated Models
There are multiple approaches, and surely books written, about how to avoid overfitting and multicollinearity in models. After all that, also, model tuning (selecting the factors to include) seems to be art as much as science. This section provides an overview of methods used, which you might consider if presented with someone elses results, or if you are trying to construct a model with a few factors on your own.
11.1.3.1 Create a Covariance Matrix
A matrix (not “the matrix”) is a mathematical term that describes what you and I would call a table. So a covariance matrix is a table composed of correlation plots that we can use to inspect the covariance (or relationship) between each possible pair of variables in our dataset.

To use the matrix, find the intersection between a column and a row containing two variables whose relationship you want to inspect. For example, in the fourth column, clay is plotted in relationship to the four other predictor variables, plus the response corn, in our model. In each plot, clay is on the X-axis, and the intersecting variable is on the Y-axis. Looking at the matrix, we notice the relationship of clay with sand and soil pH (sph) is visible. We may wonder, then, if the addition of clay to our model is improving our prediction.
11.1.3.2 Partial Correlation
Another thing we can do to look for multicollinearity is to calculate the partial correlations. Partial correlation shows the individual correlations between variables, with all other variables being held constant. What this does is allow us to quantify the correlation between two variables without worrying that both may be affected by a third variable. For example, we can look at the correlation between soil pH and soil organic matter without worrying that precipitation might be driving changes in both we could mistake for a relationship.| corn | ppt | sand | clay | sph | om | |
|---|---|---|---|---|---|---|
| corn | 1.0000000 | 0.8139276 | -0.2437413 | -0.3609330 | 0.6977065 | -0.4077095 |
| ppt | 0.8139276 | 1.0000000 | -0.0390449 | 0.2401821 | -0.7798037 | 0.4618512 |
| sand | -0.2437413 | -0.0390449 | 1.0000000 | -0.7743363 | 0.1767851 | 0.1169185 |
| clay | -0.3609330 | 0.2401821 | -0.7743363 | 1.0000000 | 0.5772645 | -0.1893945 |
| sph | 0.6977065 | -0.7798037 | 0.1767851 | 0.5772645 | 1.0000000 | 0.4490715 |
| om | -0.4077095 | 0.4618512 | 0.1169185 | -0.1893945 | 0.4490715 | 1.0000000 |
The output of partial correlation is a matrix, which cross-tablulates the correlations among every predictor variables and reports their values in a table. The output abov tells us that sand and clay are both negatively correlated with corn. That’s odd – we would expect that as sand decreases, clay would increase, or vice versa – unless, both are being impacted by a third value, silt, which is not in our model.
11.1.3.3 Cross Validation
A third way to evaluate the performance of a model and to avoid mistaking over-prediction for true model performance is to use cross-validation. I’ll confess to graduating from Iowa State and making it another 15 years in academia and industry without having a clue about how important this is. If you plan to use your model not only to test hypotheses about variable significance, but to make predictions, the cross-validation is critical.
In cross-validation, the initial data are divided into training and testing groups. The model parameters (coefficients for slopes) are solved for using the training dataset. In general, all models will better fit the data used to train them. Therefore, the predictive performance of the model is measured using the testing dataset. In this way, the true performance of the model can be measured. In addition, the effect of adding or removing factors may be measured.
We will use a technique that sounds vaguely like an adult-alternative music group – Repeated 10-Fold Cross Validation. While the name sounds scary as all get-out, how it works is (pretty) straight forward:
- Divide the data into 10 groups.
- Randomly select 9 groups and fit the regression model to them. These groups are called the “training” dataset
- Predict the responses for each observation in the tenth dataset, using the model fit to the other 9 datasets. This 10th dataset is called the “testing” dataset.
- Use linear regression to determine the strength of the relationship between the predicted value and the actual values. Review summary statistics in comparing models.
Here is the cross validation of our first yield model for Illinois and Ohio:
## Linear Regression
##
## 156 samples
## 5 predictor
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 140, 140, 141, 140, 140, 140, ...
## Resampling results:
##
## RMSE Rsquared MAE
## 10.73952 0.7632216 8.203451
##
## Tuning parameter 'intercept' was held constant at a value of TRUEWe can see in the top of the output confirmation we are working with the original 5 predictors. To measure model performance, let’s look particularly at the MRSE and Rsquared statistics at the bottom. RMSE is the Root Mean Square Error, which you earlier learned is the square root of the Mean Square Error, and equivalent to the standard deviation of our data. This is expressed in our regression output above as residual standard error. An RMSE of 10.7 means the distribution of residuals (observed values) around our model predictions has a standard deviation of about 10.7. Thus 95% of our observed values would be expected to be within 21.4 bushels (2 * 10.7) of the predicted value.
The Rsquared statistic is the same as we have seen previously, and describes the amount of variation in the observed values explained by the predicted values.
11.1.4 Tuning and Comparing Models
Here is our original model for reference. Note that sand has a negative effect (-0.33075) on yield and that it is highly significant (p=0.00248).
##
## Call:
## lm(formula = corn ~ ppt + sand + clay + om + sph, data = counties_mn_wi)
##
## Residuals:
## Min 1Q Median 3Q Max
## -42.432 -4.342 1.108 7.035 23.278
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -189.02125 22.76727 -8.302 5.52e-14 ***
## ppt 0.37140 0.02165 17.159 < 2e-16 ***
## sand -0.33075 0.10746 -3.078 0.00248 **
## clay -1.16506 0.24579 -4.740 4.92e-06 ***
## om -0.01679 0.00307 -5.469 1.85e-07 ***
## sph 24.21303 2.02991 11.928 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.61 on 150 degrees of freedom
## (3 observations deleted due to missingness)
## Multiple R-squared: 0.7651, Adjusted R-squared: 0.7573
## F-statistic: 97.71 on 5 and 150 DF, p-value: < 2.2e-16We saw above that clay was strongly correlated with both sand and soil pH. Let’s drop clay from our model and see what happens:
##
## Call:
## lm(formula = corn ~ ppt + sand + om + sph, data = counties_mn_wi)
##
## Residuals:
## Min 1Q Median 3Q Max
## -50.342 -5.438 1.410 7.135 22.276
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.031e+02 2.412e+01 -8.421 2.69e-14 ***
## ppt 3.815e-01 2.302e-02 16.575 < 2e-16 ***
## sand 5.577e-02 7.479e-02 0.746 0.457
## om -1.607e-02 3.277e-03 -4.903 2.41e-06 ***
## sph 1.953e+01 1.895e+00 10.306 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.34 on 151 degrees of freedom
## (3 observations deleted due to missingness)
## Multiple R-squared: 0.7299, Adjusted R-squared: 0.7227
## F-statistic: 102 on 4 and 151 DF, p-value: < 2.2e-16First, let’s look at the model fit. The Multiple R-squared decreased from 0.7651 to 0.7299. The residual standard error increased from 10.61 to 11.34. These would suggest the fit of the model has decreased, although we also notice the F-statistic has increased from 97.7 to 102, which suggests the model itself is more strongly detecting the combined effects of the factors on yield,
An additional statistic that we want to watch is the Adjusted R-Squared. This statistic not only takes into effect the percentage of the variation explained by the model, but how many factors were used to explain that variance. The model is penalized for according to the number of factors used: of two models that explained the same amount of variation, the one that used more factors would have a lower Adjusted R-square. We see the adjusted R-square decreased from our first model to the second.
Now let’s go back to sand. In the first model, it had a negative effect of -0.33075 and was highly significant. Now it has a positive effect of 5.577e-02 and an insignficant effect on corn yield. Remember, each factor in a linear regression model should be independent of the other factors. If we compare the other four factors, we will see their coefficients have changed slightly, but they have remained highly significant. This suggests that clay was affecting both sand content (after all, if you have more clay, you are likely to have less sand) and yield.
Let’s cross-validate the new model.
## Linear Regression
##
## 156 samples
## 4 predictor
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 140, 140, 141, 140, 140, 140, ...
## Resampling results:
##
## RMSE Rsquared MAE
## 11.18499 0.7413634 8.347023
##
## Tuning parameter 'intercept' was held constant at a value of TRUEWe see the Rsquared and RMSE (root mean square error) are statistics are slightly lower than the original model in the cross-validation, too.
Since sand was insignificant in the second model, let’s remove it and rerun our model.
##
## Call:
## lm(formula = corn ~ ppt + om + sph, data = counties_mn_wi)
##
## Residuals:
## Min 1Q Median 3Q Max
## -50.786 -5.803 1.263 6.637 22.088
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.904e+02 1.702e+01 -11.187 < 2e-16 ***
## ppt 3.724e-01 1.943e-02 19.167 < 2e-16 ***
## om -1.501e-02 2.949e-03 -5.089 1.05e-06 ***
## sph 1.863e+01 1.465e+00 12.720 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.32 on 152 degrees of freedom
## (3 observations deleted due to missingness)
## Multiple R-squared: 0.7289, Adjusted R-squared: 0.7236
## F-statistic: 136.2 on 3 and 152 DF, p-value: < 2.2e-16We see little change in the Multiple R-squared or Adjusted R-squared, but the F-statistic has again increased. Let’s cross-validate the model.
## Linear Regression
##
## 156 samples
## 3 predictor
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 140, 140, 141, 140, 140, 140, ...
## Resampling results:
##
## RMSE Rsquared MAE
## 11.15776 0.7424514 8.284529
##
## Tuning parameter 'intercept' was held constant at a value of TRUEWe see the new model fits slightly better.
We could go on and on with the process. We might try adding silt into the model to replace the sand and clay we removed. Water holding capacity was a factor in the original dataset – we might try using that as a proxy, too. But the interations we have gone through show us that bigger models are not necessarily better (not by much, in any case). While we can build complex models with multiple linear regression, it is better not to when possible.
11.2 Nonlinear Relationships
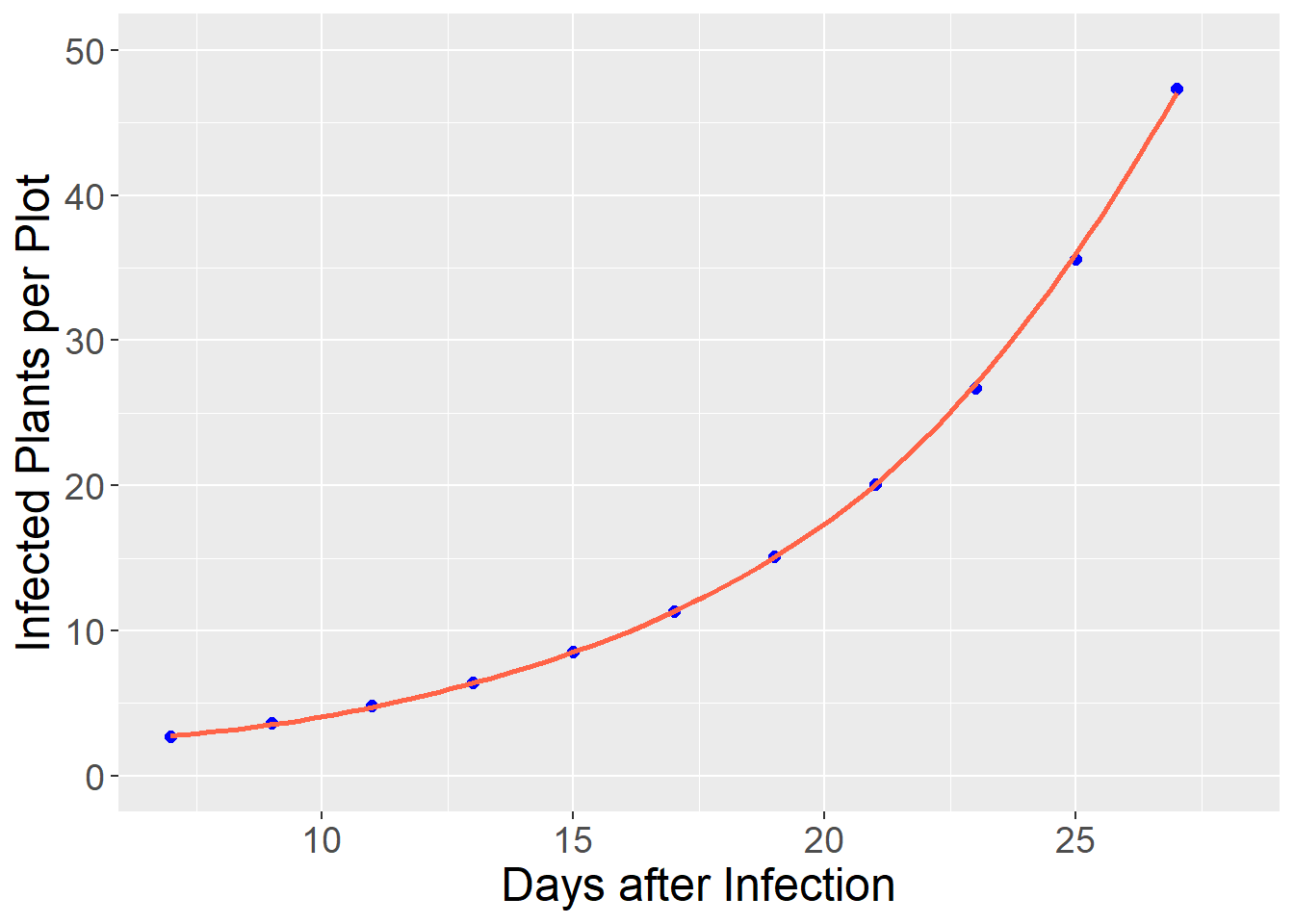
As mentioned in the introduction, there are many relationships between variables that are nonlinear – that is, cannot be modelled with a straight line. In reality, few relationships in agronomy are perfectly linear, so by nonlinear we mean relationships where a linear model would systematically over-predict or underpredict the response variable. In the plot below, a disease population (infected plants per plot) is modeled as a function of days since infection.
As with many pest populations, the number of infections increases exponentially with time. We can see how a linear model would underpredict the number of plants from 7 to 9 days after infection and again from 25 to 27 days after infection, while overpredicting the number of infected plants from 15 to 21 days after infection . Systematic overpredictions or underpredictions are called bias.

Instead, we can fit the data with an exponential model that reduces the bias and increases the precision of our model:
11.2.1 Fitting Nonlinear Responses with Linear Regression
Fitting a relationship with a simple linear regression model is simpler than fitting it with a nonlinear model, which we will soon see. Exponential relationships, like the one above can be fit by transforming the data to a new scale. This is the same concept as we used in an earlier unit to work with messy data.
11.2.1.1 Exponential Model
For example, the data above (and many exponential relationships in biology and other disciplines can be transformed using the natural log:
\[ y = log(x)\]
If our original dataset looks like:| x | y |
|---|---|
| 7 | 2.718282 |
| 9 | 3.617251 |
| 11 | 4.813520 |
| 13 | 6.405409 |
| 15 | 8.523756 |
| 17 | 11.342667 |
| 19 | 15.093825 |
| 21 | 20.085537 |
| 23 | 26.728069 |
| 25 | 35.567367 |
| 27 | 47.329930 |
| x | y | log_y |
|---|---|---|
| 7 | 2.718282 | 1.000000 |
| 9 | 3.617251 | 1.285714 |
| 11 | 4.813520 | 1.571429 |
| 13 | 6.405409 | 1.857143 |
| 15 | 8.523756 | 2.142857 |
| 17 | 11.342667 | 2.428571 |
| 19 | 15.093825 | 2.714286 |
| 21 | 20.085537 | 3.000000 |
| 23 | 26.728069 | 3.285714 |
| 25 | 35.567367 | 3.571429 |
| 27 | 47.329930 | 3.857143 |
When we fit the log of the infected plants, we see the relationship between the number of infected plants and days since infection is now linear.

We can now fit a linear model to the relationship between infected plants and days after infection.
##
## Call:
## lm(formula = log_y ~ x, data = exponential_final)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.375e-16 -3.117e-16 -3.760e-18 2.469e-16 5.395e-16
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.142e-15 3.108e-16 6.893e+00 7.12e-05 ***
## x 1.429e-01 1.713e-17 8.337e+15 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.594e-16 on 9 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: 1
## F-statistic: 6.951e+31 on 1 and 9 DF, p-value: < 2.2e-16Our linear model, from the equation above, is:
\[ log_y = 0 + 0.1429 \times x\]
Just to test the model, let’s predict the number of infected plants when x = 15
## [1] "log_y = 2.1435"We can see this value is approximately the number of infected plants 15 days after infection in the table above. Any predicted value can be transformed from the logaritm back to the original scale using the exp() function. Compare this with the original count, y, in the table above.
## [1] "y = 8.52923778043145"11.2.1.2 Parabolic
In nutrient availability and plant density models, we sometimes encounter data that are parabolic – the relationship between Y and X resembles a \(\bigcap\) or \(\bigcup\) shape. These data can be fit with a quadratic model. Remember that beast from eighth grade algebra. Don’t worry – we don’t have decompose it!
Let’s say we have data from a plant density study in corn:
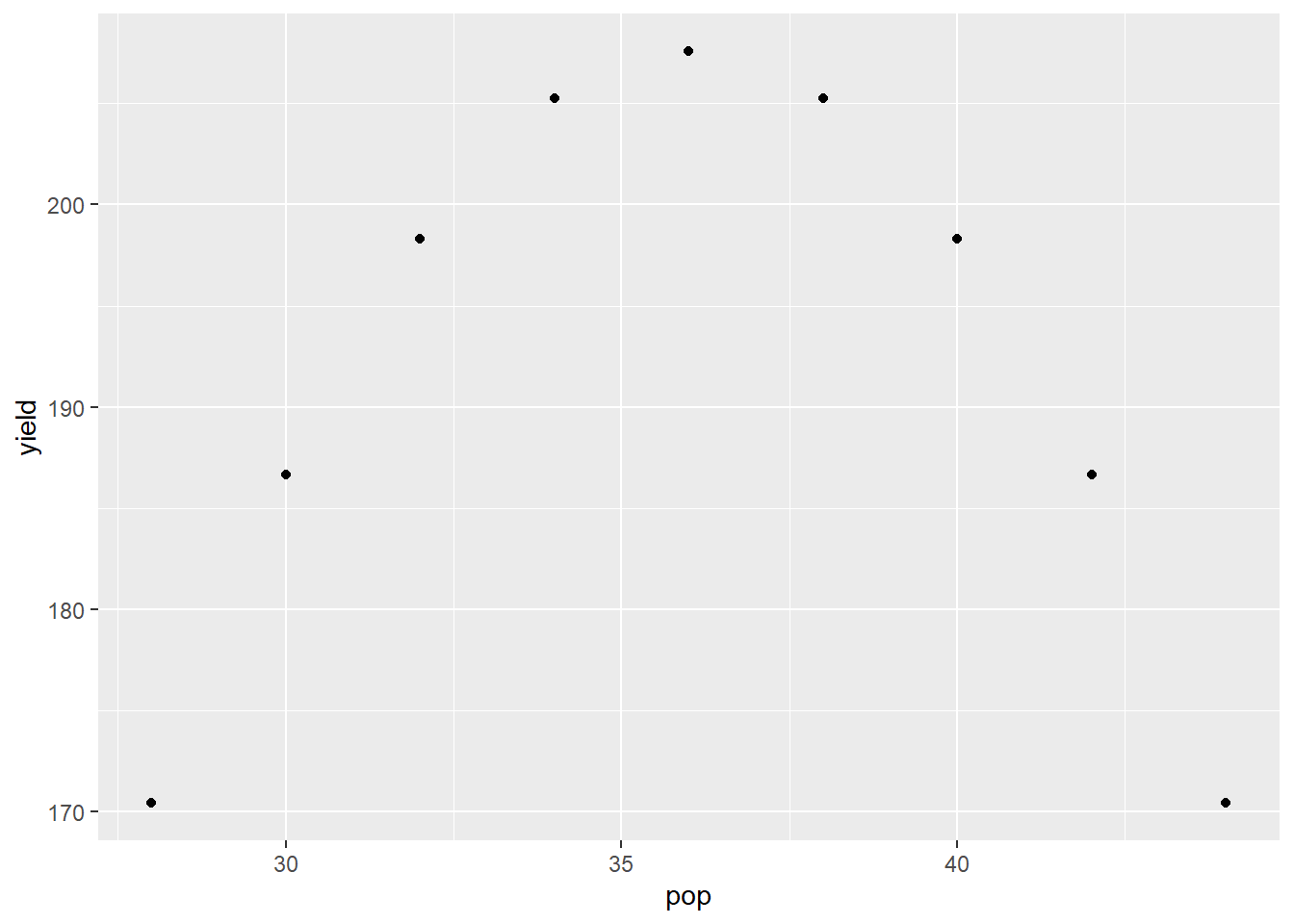
The quadratic model is:
\[ Y = \alpha + \beta X + \gamma X^2\] Where \(\alpha\) is the Y-intercept, and \(\beta\) and \(\gamma\) are the coefficients associated with \(X\) and \(X^2\). We can run this model the same as we would a simple regression.
##
## Call:
## lm(formula = yield ~ pop + pop2, data = plant_density_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.565e-14 -3.115e-14 -7.869e-15 4.033e-14 7.242e-14
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5.446e+02 1.043e-12 -5.223e+14 <2e-16 ***
## pop 4.179e+01 5.877e-14 7.111e+14 <2e-16 ***
## pop2 -5.804e-01 8.146e-16 -7.125e+14 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.718e-14 on 6 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: 1
## F-statistic: 2.538e+29 on 2 and 6 DF, p-value: < 2.2e-16This output should look very similar to the simple linear regression output. The only difference is that there are now three coefficients returned: the intercept (\(\alpha\) above), the coefficient for pop (\(\beta\) above), and the coefficent for pop2 (\(\gamma\) above).
11.2.2 Fitting Nonlinear Responses with Nonlinear Regression
Other nonlinear relationships must be fit with nonlinear regression. Nonlinear regression differs from linear regression in a couple of ways. First, a nonlinear regression model may include multiple coefficients, but only X as a predictor variable. Second, models are not fit to nonlinear data using the same approach (using least square means to solve for slope) as with linear data. Models are often to nonlinear data often do so using a “trial and error” approach, comparing multiple models before converging on the model that fits best. To help this process along, data scientists must often “guestimate” the initial values of model parameters and include that in the code.
11.2.2.1 Monomolecular
In the Monomolecular growth model, the response variable Y initially increases rapidly with increases in X. Then the rate of increase slows, until Y plateaus and does not increase further with X. In the example below, the response of corn yield to nitrogen fertilization rate is modelled with the monomolecular (asymptotic) function.
First, we load and plot the data.
corn_n_mono = read.csv("data-unit-11/corn_nrate_mono.csv")
p = corn_n_mono %>%
ggplot(aes(x=n_rate, y=yield)) +
geom_point(color="blue")
p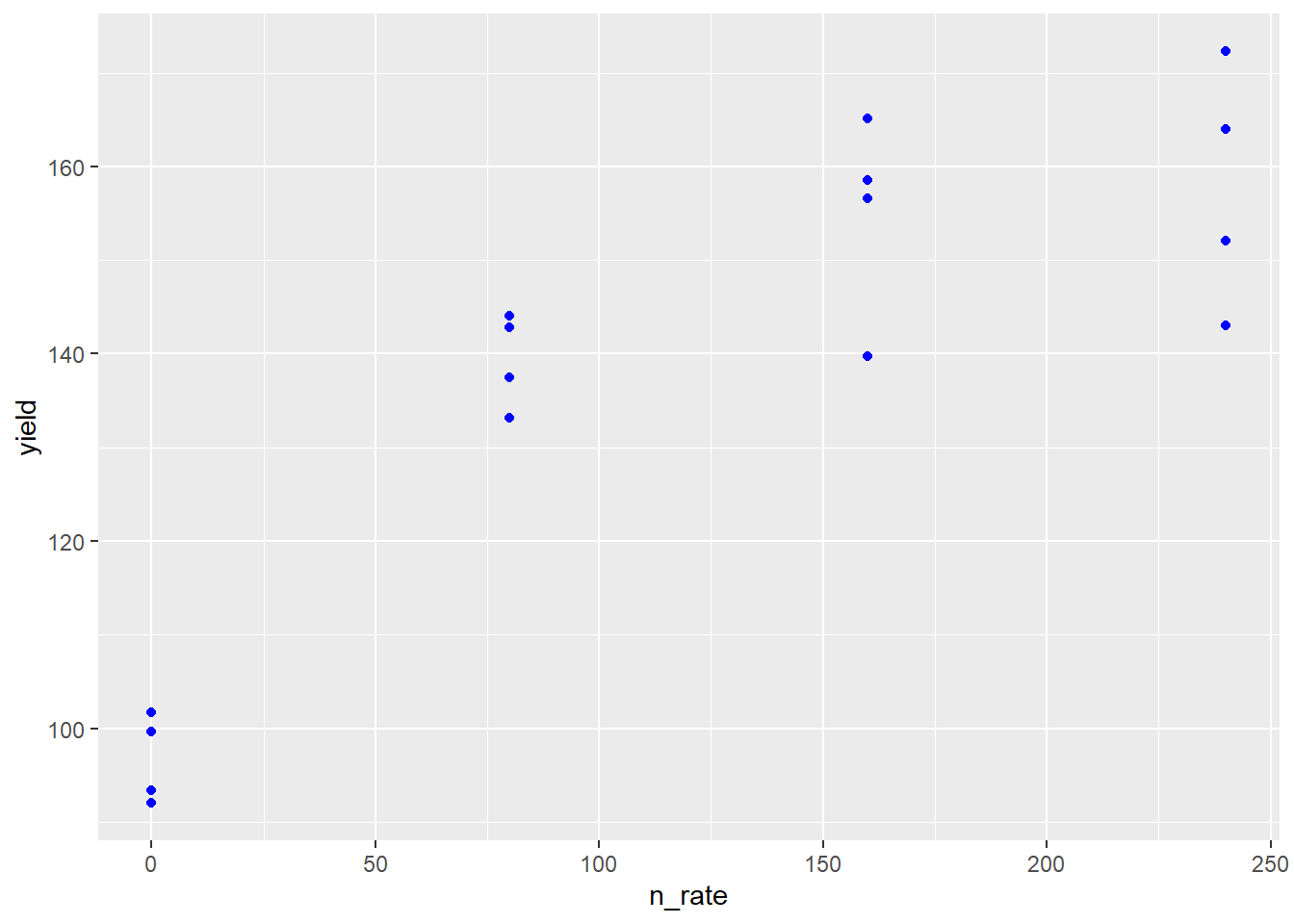
Then we fit our nonlinear model.
corn_n_mono_asym = stats::nls(yield ~ SSasymp(n_rate,init,m,plateau), data=corn_n_mono)
summary(corn_n_mono_asym)##
## Formula: yield ~ SSasymp(n_rate, init, m, plateau)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## init 160.6633 5.7363 28.01 5.24e-13 ***
## m 96.6297 4.3741 22.09 1.08e-11 ***
## plateau -4.2634 0.3019 -14.12 2.90e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8.76 on 13 degrees of freedom
##
## Number of iterations to convergence: 0
## Achieved convergence tolerance: 6.133e-08The most important part of this output is the bottom line, “Achieved convergence tolerance”. That means our model successfully fit the data.
Finally, we can add our modelled curve to our initial plot:
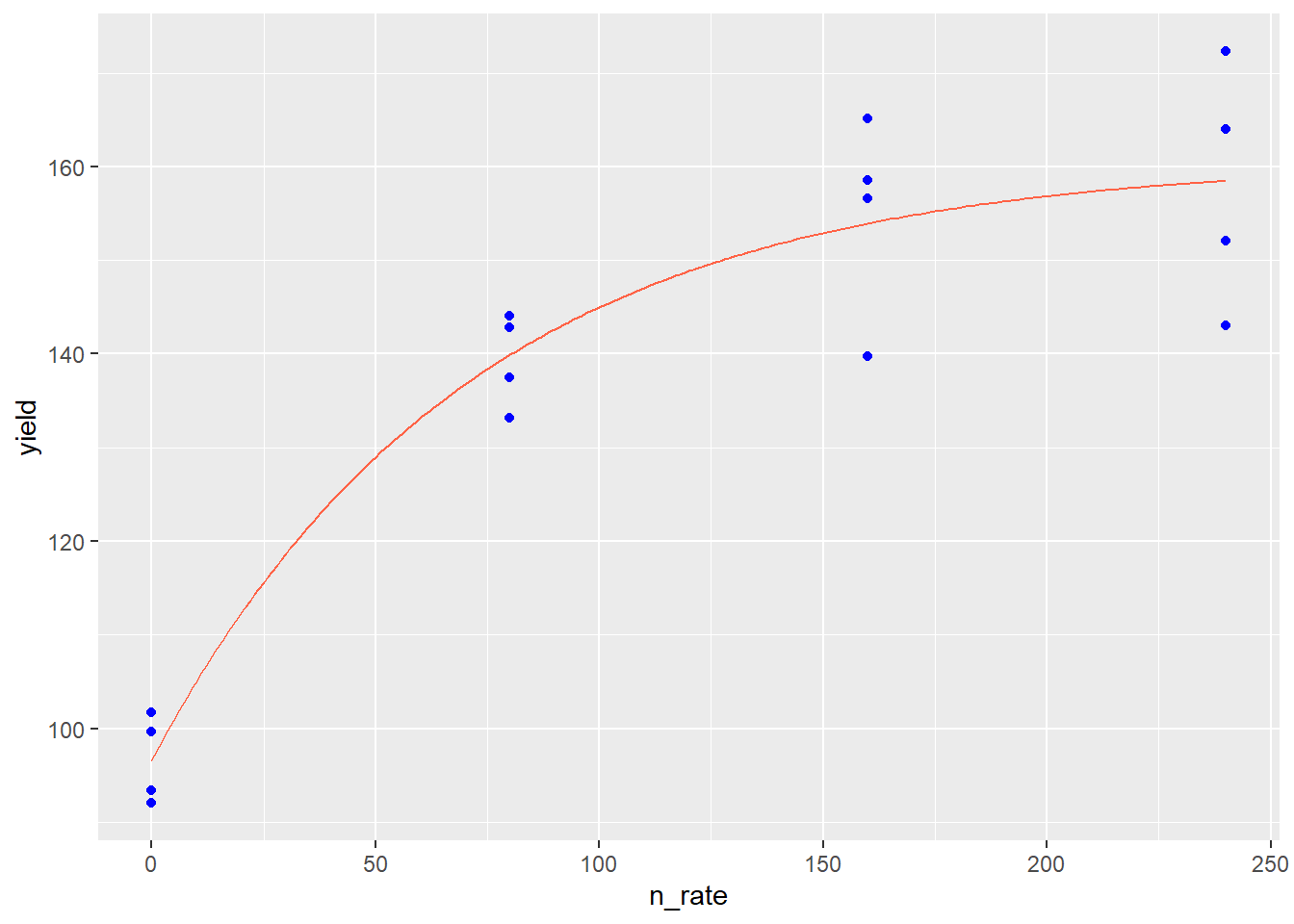
In the plot above, the points represent observed values, while the red line represents the values predicted by the monomolecular model. The monomolecular function is often used to represent fertilizer rate or soil nutrient content, since the response to many fertilizers plateaus or “maxes out”. Fertilizer rate recommendations are developed to increase fertilization up to the point where the cost of adding another unit of fertilizer exceeds the benefit of the increase in yield. The monomolecular function can also measure other “diminishing returns” responses, such as the response of photosynthesis to increasing leaf area.
11.2.2.2 Logistic Model
The Logistic and model is often used in “growth analysis”, studies that highlight patterns of plant growth, particularly cumulative biomass accumulation over time. Data generally follow a “sigmoidal”, or S-shaped, pattern. In early growth the rate of biomass accumulation slowly increases. In the intermediate growth phase, biomass accumulation is rapid and linear. In the final growth phase, the rate of growth decreases and, if the trial is long enough, may plateau.
In the plot below, total dry matter accumulation (tdm) is shown in relation to days after emergence (dae).

The “S” shape of the data is very pronounced. Next, we fit a logistic growth curve to the data:
##
## Formula: tdm ~ SSlogis(dae, Asym, xmid, scal)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## Asym 857.5043 11.7558 72.94 2.12e-07 ***
## xmid 59.7606 0.7525 79.42 1.51e-07 ***
## scal 10.8261 0.6574 16.47 7.96e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 14.64 on 4 degrees of freedom
##
## Number of iterations to convergence: 0
## Achieved convergence tolerance: 3.029e-06We see again in the output that the model achieved convergence tolerance. Another thing to note is the “Number of iterations to convergence”. It took this model 9 steps to fit the data. The algorithm will typically quit after 50 unsuccessful attempts. When that occurs, it may be an indication the data should be fit with a different model.
Here is our data with the fitted prediction model:

We can see this again illustrated in the next plot, which illustrates the effect of wetting period on the intensity of wheat blast.

We fit the data with the logistic model.
##
## Formula: intensity ~ SSlogis(wetting_period, Asym, xmid, scal)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## Asym 0.83092 0.01606 51.74 3.50e-09 ***
## xmid 19.13425 0.33505 57.11 1.94e-09 ***
## scal 2.95761 0.28825 10.26 5.00e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.02552 on 6 degrees of freedom
##
## Number of iterations to convergence: 1
## Achieved convergence tolerance: 4.024e-06Convergence criteria was met. Here is the data plotted with the logistic model.
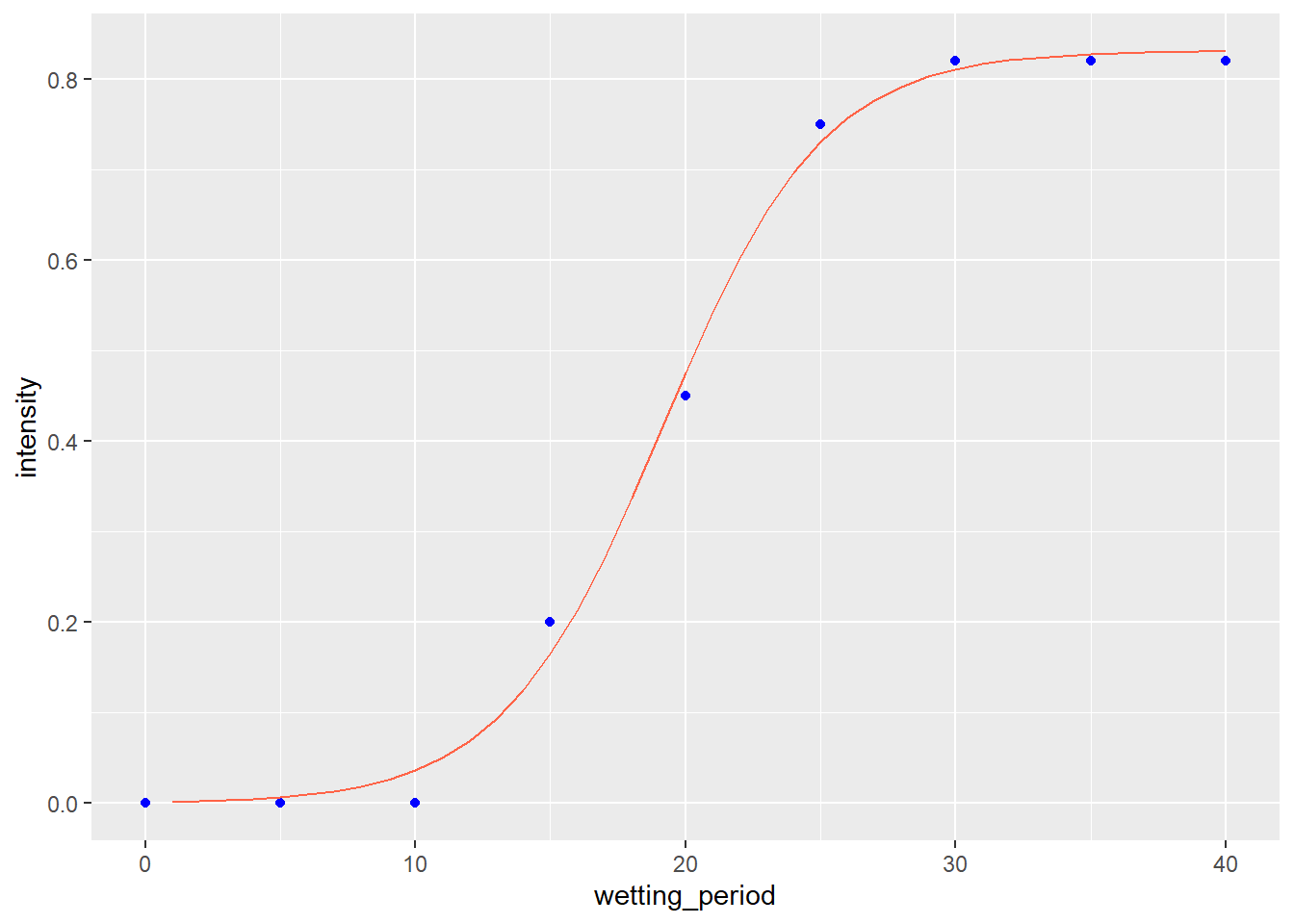
11.2.2.3 Starting Variable Values
As mentioned earlier, nonlinear regression algorithms can be difficult to use in that they don’t fit a regression model using the least squares approach. Instead, nonlinear regression “nudges” the different coefficients in its equation until it zeros in on coefficient values that best fit the data. Often, traditionally, algorithms have not been able to solve for these coefficients from scratch. The user would have to provide initial coefficient values and hope they were close enough to true values that the nonlinear algorithm could then fit the curve.
What a pain in the butt. While some coefficients could be easily guessed, others required more complex calculations. With R, some packages have introduced “self-starting” non-linear models that do not require the user to enter initial values for coefficients. I have used those to create the examples above and we will cover them in the exercises. Just be aware, were you to get into more intensive nonlinear modelling, that you may need to specify those variables.
11.3 Summary
Multivariate models (those that model yield or another response to multiple variables) are very powerful tools for unlocking the mysteries of how changes in environment drive what we observe in our research. However, they require skill to use. Remember that more variables do not automatically make a better model. Too many variables can cause our model to overfit our original data, but be less accurate or unbiased in fitting future datasets. Ask yourself whether it makes sense to include each variable in a model. Covariance matrixes and partial correlations can help us identify predictor variables that may be correlated with each other instead of the response variable.
Cross validation is also an important tool in assessing how a model will work with future data. In this unit, we learned a common practice, 10-fold cross validation, in which the data were divided into 10 groups. Each group took turns being part of the datasets used to train the model, and the dataset used to test it.
Finally, nonlinear regression is used to fit variables that have a nonlinear relationship. Untlike multiple linear regression, there is usually only one predictor variable in non-linear regression. In addition, nonlinear regression is often based on a theoretical relationship between the predictor and response variable. In this unit, we focused on two models: the monomolecular model for relationships between yield and soil fertility, and the logistic model for predicting growth of plants and other organisms.