Chapter 6 Multiple Treatment Trials
Here is our course, so far, in a nutshell:
- statistics is all about populations
- when we compare treatments, we are actually comparing populations that have been exposed to different products or management
- when we can measure every individual in that population, we can use the Z-distribution to describe their true population means and variance
- most of the time in agricultural research, however, we must use a samples (subsets from those populations) to estimate their population means and variance
- when we use the sample mean to estimate the population mean, we use the t-distribution to descibe the distribution of sample means around the mean of their values
- the distribution of sample means can be used to calculate the probability (the p-value) the true population mean is a hypothetical value
- in a paired t-test of two populations, we create a new population of differences, and calculate the probability its mean is zero
- proper hypotheses and alphas (maximum p-values for significance) can reduce the likelihood we conclude populations are different when they are likely the same, or the same when they are likely different
I include this brutal distillation so you can see how the course has evolved from working with complete populations to samples, from “true” or “certain” estimates of population means to estimates, from working with single populations to comparing differences between two populations.
In the last two units, we learned how to design and evaluate the results of side-by-side trials: trials in fields or parts of fields were divided into two populations that were managed with different treatments or practices. This was a practical, powerful, jumping-off point for thinking about experiments and their analyses.
Let’s face it, however: if we only compared two treatments per experiment in product testing or management trials, our knowledge would advance at a much slower pace. So in the next three units, we will learn how to design and evaluate trials to test multiple categorical treatments. By categorical, we mean treatments we identify by name, not quantity. Treatments that, in general, cannot be ranked. Hybrids are a perfect example of categorical treatments. Herbicides, fungicides, or fertilzers that differ in brand name or chemical composition are also categorical treatments. Comparisons of cultural practices, such as tillage systems or crop rotations are categorical treatments as well.
6.1 Case Study
For our case study, we will look at a comparison of four hybrids from the Marin Harbur seed company. We will compare hybrids MH-052672, MH-050877, MH-091678, and MH-032990, which are not coded by relative maturity or parent lines, but represent some of the owner’s favorite Grateful Dead concerts:
- MH-052672 has a great early disease package and is ideal for environments that have heavy morning dews
- MH-050877 is very resilient in poor fertility soils and among the last to have its leaves fire under low nitrogen conditions. It can also grow well on everything from flatlands to mountains.
- MH-091678 has a very strong root base that will not be shaken down by late-season wind storms
- MH-032990 offers a very rich performance and responds well to additional inputs. (This one catches growers’ eyes at every field day – not to blow our own horn.)
| plot_number | Hybrid | Yield | col | row |
|---|---|---|---|---|
| 1 | MH-050877 | 189.5 | 1 | 1 |
| 2 | MH-052672 | 186.4 | 1 | 2 |
| 3 | MH-091678 | 196.9 | 1 | 3 |
| 4 | MH-050877 | 191.2 | 1 | 4 |
| 5 | MH-091678 | 191.8 | 2 | 1 |
| 6 | MH-032990 | 198.9 | 2 | 2 |
The hybrids were grown in a field trial with four replications as shown below.

The arrangement of treatments above is a completely randomized design. This means the hybrids were assigned at random among all plots – there was no grouping or pairing of treatments as in our side-by-side trials earlier.
This design – to be honest – is used more often in greenhouse or growth chamber research where the soil or growing media are more uniform. Still, it is the most appropriate design to start with in discussing multiple treatment trials.
6.2 The Linear Additive Model
In order to understand how we will analyze this trial, let’s plot out our data.
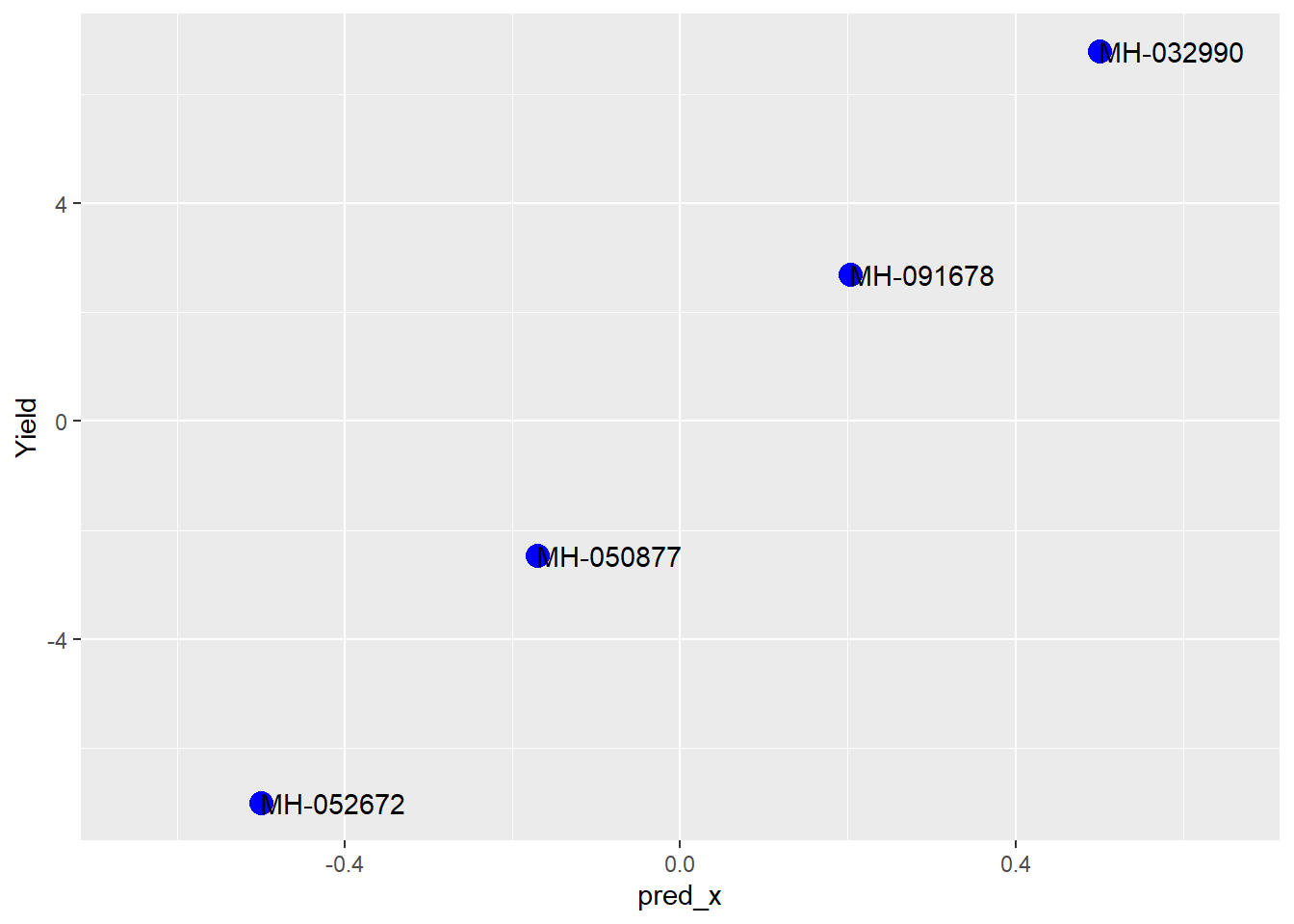
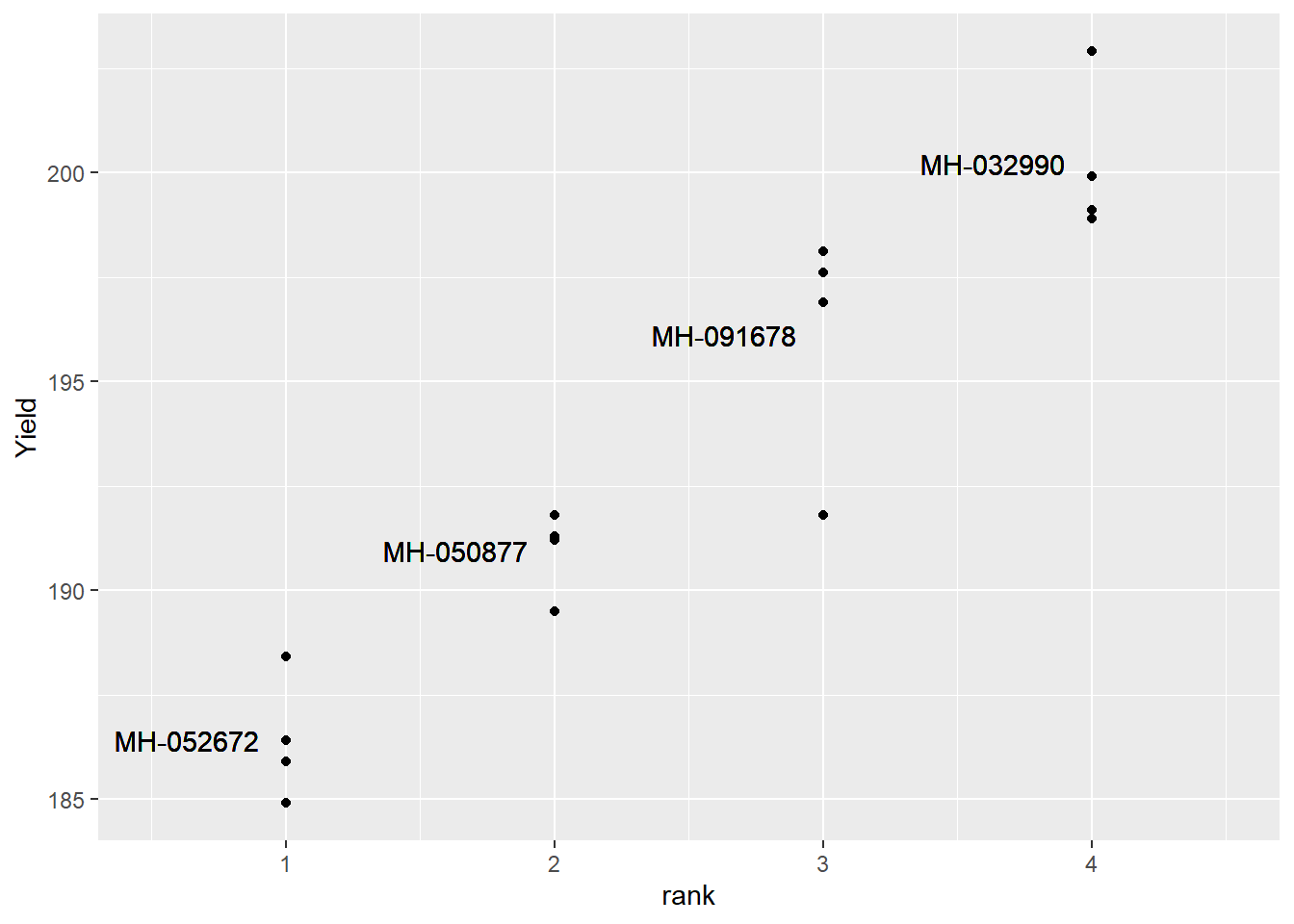
Our treatment means are shown below:
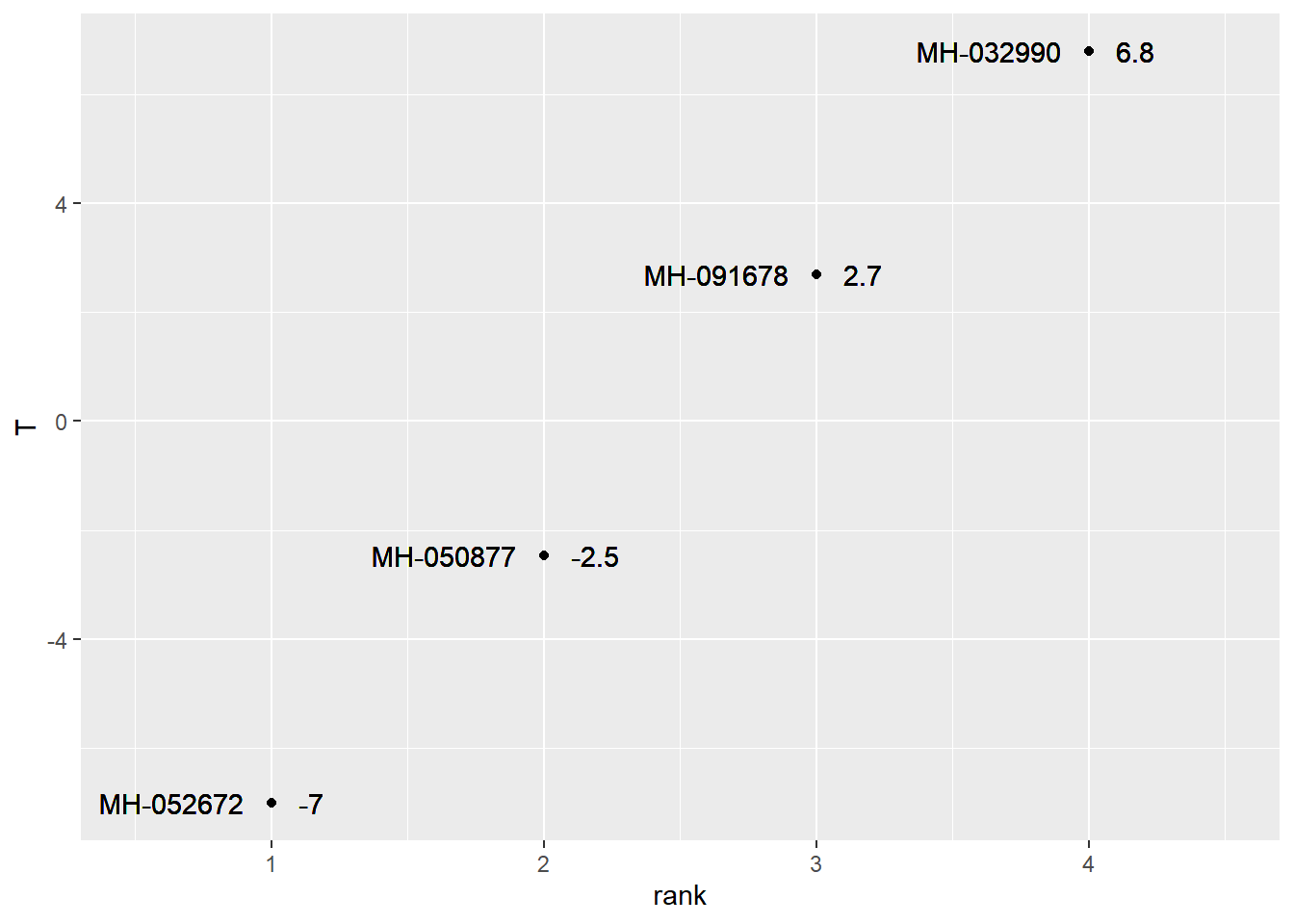
We can see the plot effects as well.
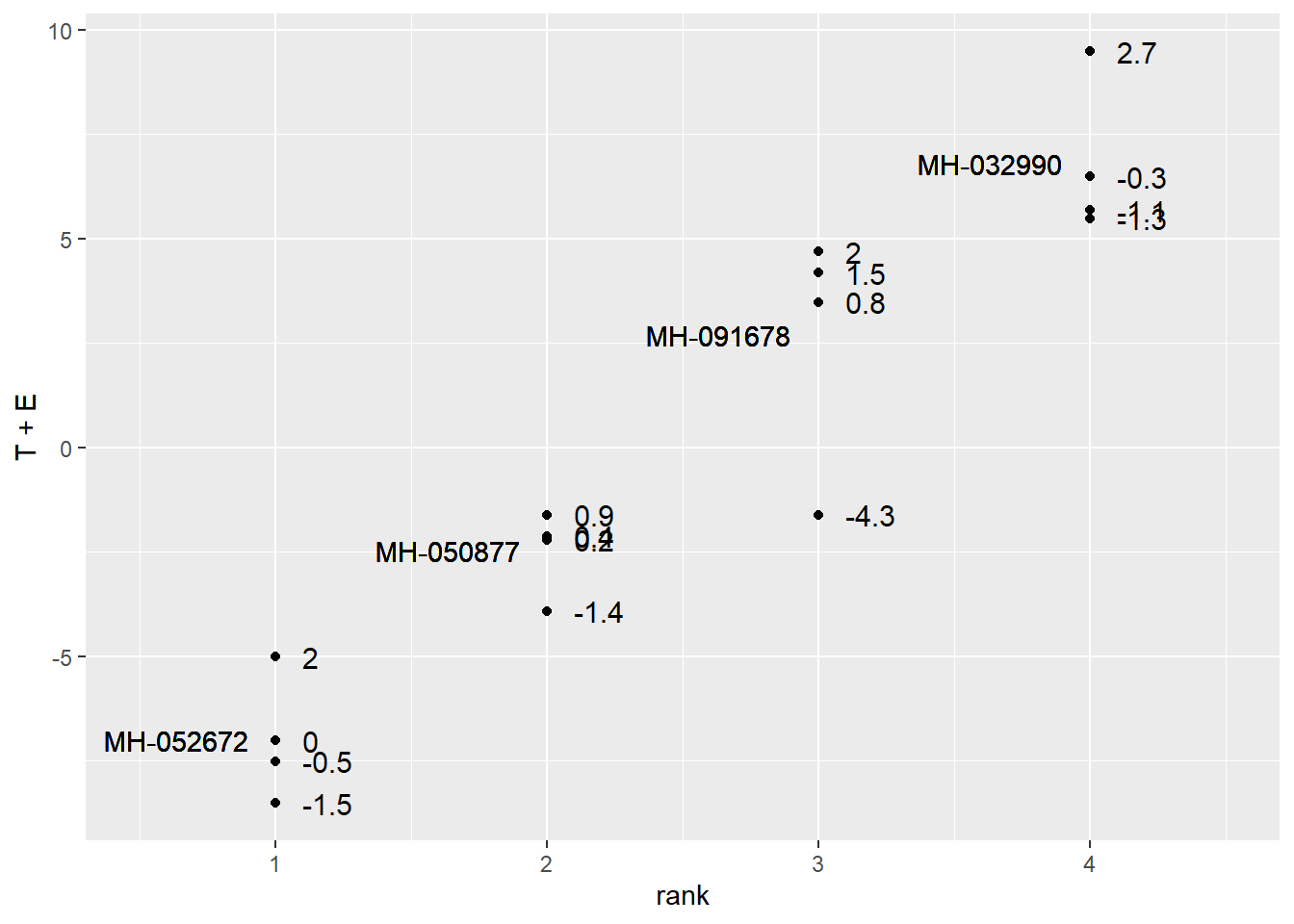
We can observe the linear model using this table:
| Hybrid | mu | T | E | Yield (mu + T + E) |
|---|---|---|---|---|
| MH-032990 | 193.4 | 6.8 | -1.3 | 198.9 |
| MH-032990 | 193.4 | 6.8 | -1.1 | 199.1 |
| MH-032990 | 193.4 | 6.8 | 2.7 | 202.9 |
| MH-032990 | 193.4 | 6.8 | -0.3 | 199.9 |
| MH-050877 | 193.4 | -2.5 | -1.4 | 189.5 |
| MH-050877 | 193.4 | -2.5 | 0.2 | 191.2 |
| MH-050877 | 193.4 | -2.5 | 0.9 | 191.8 |
| MH-050877 | 193.4 | -2.5 | 0.4 | 191.3 |
| MH-052672 | 193.4 | -7.0 | 0.0 | 186.4 |
| MH-052672 | 193.4 | -7.0 | -1.5 | 184.9 |
| MH-052672 | 193.4 | -7.0 | 2.0 | 188.4 |
| MH-052672 | 193.4 | -7.0 | -0.5 | 185.9 |
| MH-091678 | 193.4 | 2.7 | 0.8 | 196.9 |
| MH-091678 | 193.4 | 2.7 | -4.3 | 191.8 |
| MH-091678 | 193.4 | 2.7 | 2.0 | 198.1 |
| MH-091678 | 193.4 | 2.7 | 1.5 | 197.6 |
Just as in the side-by-side trials, our statistical test is based on the ratio of the variation among treatment means to the variation among observations within each treatment.

6.3 Analysis of Variance
Chances are if you have spent time around agronomic research you have probably heard of ANOVA.

A Nova
No, not that fine example of Detroit muscle, but a statistical test, the Analysis of Variance (ANOVA). The ANOVA test performs the comparison described above when there are more than two more populations that differ categorically in their management. I’ll admit the nature of this test was a mystery to me for years, if not decades. As the name suggests, however, it is simply an analysis (a comparison, in fact) of the different sources of variation as outlined in our linear additive model. An Analysis of Variance tests two hypotheses:
- Ho: There is no difference among population means.
- Ha: There is a difference among population means.
In our hybrid trial, we can be more specific:
- Ho: There is no difference in yield among populations planted with four different hybrids.
- Ha: There is a difference in yield among populations planted with four different hybrids.
But the nature of the hypotheses stays the same.
6.4 The F statistic
The Analysis of Variance compares the variance from the treatment effect to the variance from the error effect. It does this by dividing the variance from treatments by the variance from Error:
\[F = \frac{\sigma{^2}_{treatment}}{\sigma{^2}_{error}} \]
The \(F-value\) quanitfies the ratio of treatment variance to error variance. As the ratio of the variance from the treatment effect to the variance from the error effect increases, so does the F-statistic. In other words, a greater F-statistic suggests a greater treatment effect – or – a smaller error effect.
6.5 The ANOVA Table
At this point, it is easier to explain the Analysis of Variance by working with the output table of statistics.
| term | df | sumsq | meansq | statistic | p.value |
|---|---|---|---|---|---|
| Hybrid | 3 | 434.1275 | 144.709167 | 38.44388 | 2e-06 |
| Residuals | 12 | 45.1700 | 3.764167 | NA | NA |
As we did with the t-test a couple of units ago, lets go through the ANOVA output above column by column, row by row.
6.5.1 Source of Variation
The furthest column to the left, term specifies the two effects in our linear additive model: the Hybrid and Residual effects. As mentioned in the last chapter, the term Residual is often used to describe the “leftover” variation among observations that a model cannot explain. In this case, it refers to the variation remaining when the Hybrid effect is accounted for. This column is also often referred to as the Source of Variation column.
6.5.2 Sum of Squares
Let’s skip the df column for a moment to expain the column titled sumsq in this output. This column lists the sums of squares associated with the Hybrid and Residual Effect. Remember, the sum of squares is the sum of the squared differences between the individuals and the population mean. Also, we need to calculate the sum of squares before calculating variance
The Hybrid sum of squares based on the the difference between the treatment mean and the population mean for each observation in the experiment. In the table below we have mu, the population mean, and T, the effect or difference between the treatment mean and mu. We square T for each of the 16 observations to create a new column, T-square:
| Hybrid | mu | T | T-square |
|---|---|---|---|
| MH-032990 | 193.4125 | 6.7875 | 46.070156 |
| MH-032990 | 193.4125 | 6.7875 | 46.070156 |
| MH-032990 | 193.4125 | 6.7875 | 46.070156 |
| MH-032990 | 193.4125 | 6.7875 | 46.070156 |
| MH-050877 | 193.4125 | -2.4625 | 6.063906 |
| MH-050877 | 193.4125 | -2.4625 | 6.063906 |
| MH-050877 | 193.4125 | -2.4625 | 6.063906 |
| MH-050877 | 193.4125 | -2.4625 | 6.063906 |
| MH-052672 | 193.4125 | -7.0125 | 49.175156 |
| MH-052672 | 193.4125 | -7.0125 | 49.175156 |
| MH-052672 | 193.4125 | -7.0125 | 49.175156 |
| MH-052672 | 193.4125 | -7.0125 | 49.175156 |
| MH-091678 | 193.4125 | 2.6875 | 7.222656 |
| MH-091678 | 193.4125 | 2.6875 | 7.222656 |
| MH-091678 | 193.4125 | 2.6875 | 7.222656 |
| MH-091678 | 193.4125 | 2.6875 | 7.222656 |
We then sum the squares of T to get the Hybrid sum of squares.
## [1] 434.1275We use a similar approach to calculate the Error (or Residual) sum of squares. This time we square the error effect (the difference between the observed value and the treatment mean) for each observation in the trial.
| Hybrid | mu | E | E-square |
|---|---|---|---|
| MH-032990 | 193.4125 | -1.30 | 1.6900 |
| MH-032990 | 193.4125 | -1.10 | 1.2100 |
| MH-032990 | 193.4125 | 2.70 | 7.2900 |
| MH-032990 | 193.4125 | -0.30 | 0.0900 |
| MH-050877 | 193.4125 | -1.45 | 2.1025 |
| MH-050877 | 193.4125 | 0.25 | 0.0625 |
| MH-050877 | 193.4125 | 0.85 | 0.7225 |
| MH-050877 | 193.4125 | 0.35 | 0.1225 |
| MH-052672 | 193.4125 | 0.00 | 0.0000 |
| MH-052672 | 193.4125 | -1.50 | 2.2500 |
| MH-052672 | 193.4125 | 2.00 | 4.0000 |
| MH-052672 | 193.4125 | -0.50 | 0.2500 |
| MH-091678 | 193.4125 | 0.80 | 0.6400 |
| MH-091678 | 193.4125 | -4.30 | 18.4900 |
| MH-091678 | 193.4125 | 2.00 | 4.0000 |
| MH-091678 | 193.4125 | 1.50 | 2.2500 |
We again sum the squared error effects to get the Error or Residual sum of squares.
## [1] 45.176.5.3 Degrees of Freedom
The df column above refers to the degrees of freedom. Remember, the variance is equal to the sum of squares, divided by its degrees of freedom. The hybrid sum of squares is simply the number of treatments minus 1. In this example, there were 4 hybrids, so there were three degress of freedom for the Hybrid effect. The concept behind the hybrid degrees of freedom is that if we know the means for three hybrids, as well as the population mean, then we can calculate the fourth hybrid mean, as it is determined by the first three hybrids and the population mean. Degrees of freedom are a weird concept, so try not to overanalyze them.
The degrees of freedom for the error or residual effect are a little more confusing. The degrees of freedom are equal to the Hybrid degrees of freedom, times the number of replications. In this case, the error degrees of freedom are 12. The idea behind this is: if for a hybrid you know the values of three observations, plus the hybrid mean, you can calculate the value of the fourth observation.
6.5.4 Mean Square
In the Analysis of Variance, the Sum of Squares, divided by the degrees of freedom, is referred to as the “Mean Square”. As we now know, the mean squares are also the variances attributable to the Hybrid and Error terms of our linear model. Our hybrid mean square is about 144.7; the error mean square is about 3.8.
6.5.5 F-Value
THe F-Value, as introduced earler, is equal to the hybrid variance, divided by the error variance. In the ANOVA table, F is calculated as the hybrid mean square divided by the error mean square. When the F-value is 1, it means the treatment effect and error effect have equal variances, and equally describe the variance among observed values. In other words, knowing the treatment each plot received adds nothing to our understanding of observed differences.
6.5.6 P-value
The F-value is the summary calculation for the relative sizes of our Hybrid and Error variances. It’s value is 38.4, which means the Hybrid variance is over 38 times the size of the Error variance. In other words, the Hybrid variance accounts for much, much more of the variation in our observations than the Error variance. But, given this measured F-value, what is the probability the true F-value is 1, meaning the Hybrid and Error variances are the same?
To calculate the probability our F-value could be the product of chance, we use the F-distribution. The shape of the F-distribution, like the t-distribution, changes with the number of replications (which changes the Error degrees of freedom). It also changes with the treatment degrees of freedom.
Please click the link below to access an app where you will be able to adjust the number of treatments and number of replications:
https://marin-harbur.shinyapps.io/06-f-distribution/
Adjust those two inputs and observe the change in the response curve. In addition, adjust the desired level of significance and obsere how the shaded area changes. Please ignore the different color ranges under the curve when you see them: any shaded area under the curve indicates significance.
The F-distribution is one-tailed – we are only interested in the proportion remaining in the upper tail. If we were to visualize the boundary for the areas representing \(P\ge0.05\) for our example above, we would test whether F was in the following portion of the tail.
As we can see, our observed F of 38.4 is much greater than what we would need for significance at \(P\ge0.05\). What about \(P\ge0.01\)?
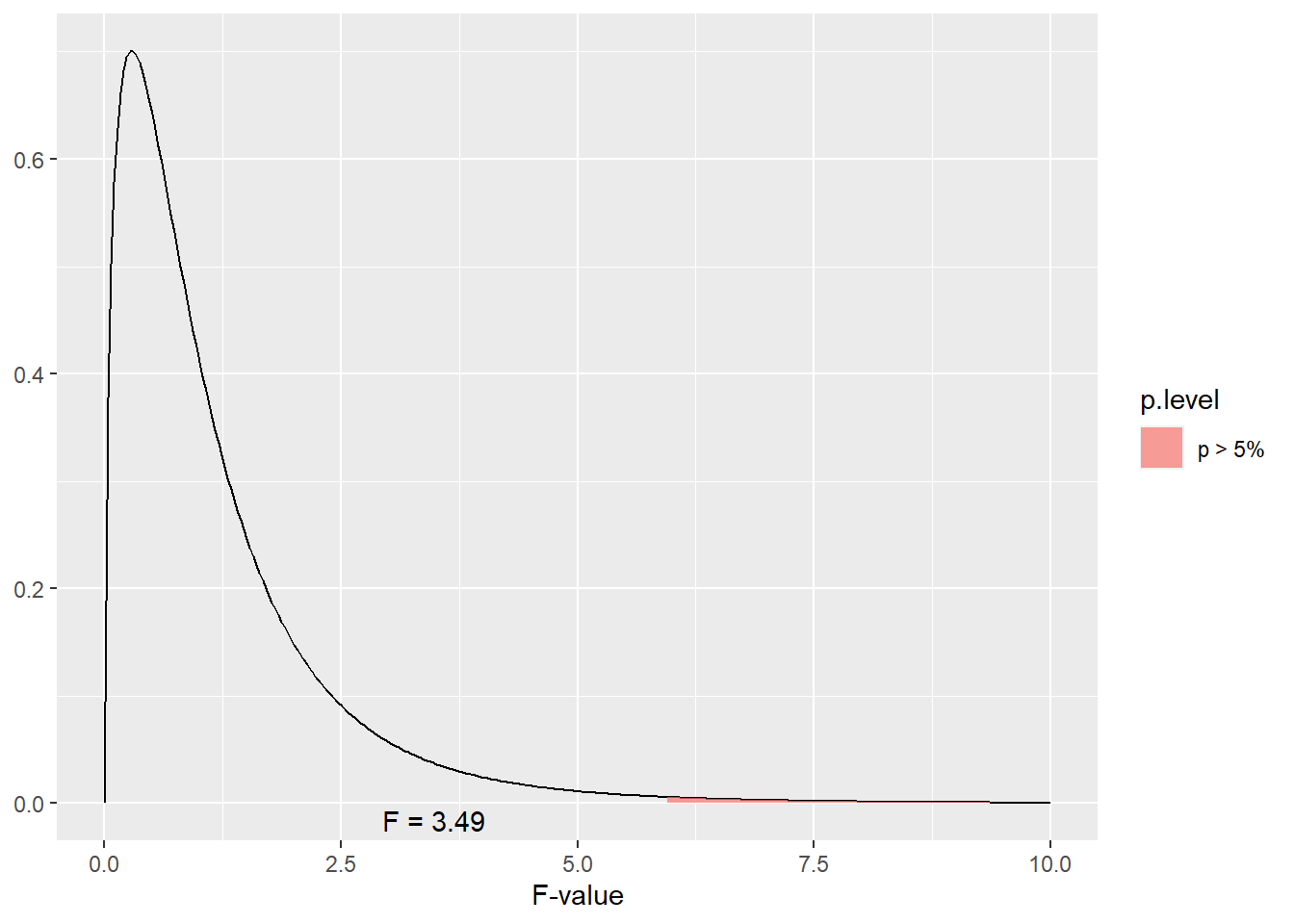
Our value is also way beyond the F-value we would need for \(P\ge0.05\).
6.6 Visualizing How the Anova Table Relates to Variance
Please follow the following link to an app that will allow you to simulate a corn trial with three treatments:
https://marin-harbur.shinyapps.io/06-anova-variances/
Use your observations to address the following four questions in Discussion 6.1:
- What do you observe when distance between the trt means increases?
- what do you observe when the pooled standard deviation decreases?
- Set the treatment means to treatment 1 = 180, treatment 2 = 188, and treatment 3 = 192. What do you observe about the shapes of the distribution curve for the treatment means (black curve) and treatment 2 (green curve)?
- What does an F-value of 1 mean?